【深度报告——金融工程】衍生品量化择时系列专题(八):基于聚类算法的商品基本面大类研究
报告日期:2022年9月4日
★研究背景:
在商品基本面量化领域,模型构建和数据处理是两个主要的研究方向。本系列之前的报告着重讨论了基本面量化的模型构建,而本报告则以数据处理为出发点,力求从数据层面给予模型更好的特征输入。
★模型构建:
数据收集:本报告数据均来自于繁微数据平台,数据类别包含库存、情绪、原料、终端等数据;指标来源涵盖了Bloomberg、SHFE、海关总署等数据。总数据量达到392个。
数据处理:对原始数据的处理包括频率调整、标准化、可得性处理、数据扩充、移仓换月处理;
聚类模型:聚类指通过某个特定标准将数据划分为不同的类或簇,使得同一个类别内数据的相似性尽可能大。本报告尝试采用DTW+KMeans的方式对期货的基本面数据进行聚类;
数据降维:本报告降维方式以PCA和KPCA为主。
回测框架:采用OLS多元线性拟合,并进行滚动回归。
★模型结果:
根据报告最后构建的多品种横截面多空模型,策略整体的年化收益达到26.85%,年化波动11.54%,夏普值2.12,最大回撤-13.62,胜率0.61。由于回测阶段未考虑到交易滑点,真实年化收益率应当略低于该值。
★风险提示:
市场风格的切换会造成特征有效性发生变化,导致模型效果下降。
1
研究背景
在商品基本面量化领域,模型构建和数据处理是两个主要的研究方向。本系列之前的报告着重讨论了基本面量化的模型构建,而本报告则以数据处理为出发点,力求从数据层面给予模型更好的特征输入。对输入特征的考量取决于模型的回测结果,回测过程采用滚动回归的方式,这样不仅可以避免模型过拟合的风险出现,同时也尽可能还原该策略用于实盘交易的收益情况。
由于商品基本面数据量较多,在作为特征输入给模型之前,需要对数据进行降维处理,这样可以提升模型的稳健性,同时也降低模型计算的复杂程度。传统的降维方式是采用主成分分析法(PCA降维),在每次滚动更新模型之前,对数据进行全量降维。本文的重点在于考察商品基本面数据不同类别的预测能力,基本面数据的分类通常按照商品产业链上下游关系或者分析师的主观判断进行分类,然而在数据的时序结构层面同一类的数据可能存在较大的差异,如何将在时序上具有较强相关性的数据归到一类是一个值得思考的问题。一个容易想到的方式是根据时序数据之间的相关性进行分类,而该方式无法准确识别数据在时序上的特征的相似性,故本报告通过计算两个数据之间的DTW距离来衡量其相似性,并且通过对大类内部的数据进行降维处理来考察各类数据的预测能力。
总之,在商品基本面量化的研究过程中,数据处理的目的就是从有限的数据量之中挖掘出尽可能多的有效信息,同时也应当考虑模型的运行效率。无论是引入数据的差分、同比、环比等指标,还是对数据进行标准化、降维等处理,都是基于此为目的的。
2
模型构建
2.1、数据收集与初步筛选
本报告数据均来自于繁微数据平台,繁微是东证期货自行研发的投研一体式智能投顾平台,该平台集成了目前市面上绝大多数大宗商品数据来源,本报告收集了“铜”目录下所有的基本面数据。数据类别包含库存、情绪、原料、终端等数据;指标来源以Wind和上海钢联为主,也涵盖了Bloomberg、SHFE、海关总署等数据。总数据量达到392个。
由于基本面数据数据经常出现缺失值以及数据停更的情况,首先对数据进行初步筛选。本阶段数据选取时段为2015年1月1日-2022年7月26日,为保证数据在时间上的连续性,将2016年1月1日之前未发布的指标删除,同时将2022年之后停更的数据指标删除;此外,为剔除超低频数据的影响,将数据点个数不超过50个的数据剔除(此步骤主要剔除半年度和年度数据)。经过初步筛选后,数据量从392下降至198个。


2.2、数据处理
在经过数据的初步筛选之后,认为保留下的数据具有预测价值,接下来需要进一步对这些数据进行处理,操作如下:
频率调整:基本面的原始数据多为低频数据(月频或周频),为便于处理,将所有数据前值填充为日频数据;
标准化:对所有填充后的数据进行z-score标准化处理,提高数据之间的可比性;
可得性处理:基本面数据的获取存在一定的滞后性,即某一期的数据需要在一定时段之后才能够得到,若未作调整直接进行回测,相当于拿当时无法获取的当期数据进行预测,存在调用“未来数据”的风险,故根据不同指标的滞后期数进行相应调整;
数据扩充:为补充时序数据周期性的变化信息,针对每个指标分别进行月度、季度、年度的差分和比值计算以扩充指标数量。
移仓换月处理:为避免期货展期导致的价格影响,本报告以期货复权价格进行回测;
2.3、聚类模型
聚类指通过某个特定标准将数据划分为不同的类或簇,使得同一个类别内数据的相似性尽可能大。本报告尝试采用DTW+KMeans的方式对期货的基本面数据进行聚类。
2.3.1、DTW
由于基本面数据为时间序列数据,无法通过计算点与点之间的欧式距离或曼哈顿距离来衡量数据之间的相似性。对于时序数据,可以通过“锁步度量”来计算序列的相似性,即依次计算两个序列各点之间的欧式距离再求和,然而这种计算方式存在一系列问题:该方法无法处理序列不同步、步长不一致、长短不一等问题,最重要的是,该方法无法识别数据的时序特征。故本报告采用动态时间规整算法(Dynamic Time Warping,DTW)来计算时序数据之间的“距离”,该算法是一种“弹性度量”算法,DTW通过把时间序列进行延伸和缩短,来计算两个时间序列性之间的相似性。


如上图所示,上下两条实线代表两个时间序列,时间序列之间的虚线代表两个时间序列之间的相似的点。DTW使用所有这些相似点之间的距离的和,称之为归整路径距离(Warp Path Distance)来衡量两个时间序列之间的相似性。
为更加直观地表述,将两个序列通过n*n的矩阵进行展开,每一个单元格表示序列X上的某一点到序列Y上某一点的距离。左图展示了“锁步度量”的计算方式,该度量路径是从左下直接连接到右上方,表明两条序列之间一一对应的关系;而右图则展示了“弹性度量”的方式,该度量路径通过选择最小化距离之和的方式计算两序列之间的相似性。

DTW算法在寻找最短路径的过程中需要满足三个约束条件:
1)边界条件:表示两条序列首尾必须匹配,各部分的先后次序匹配;
2)连续性: 这条约束表示在匹配过程中多对一和一对多的情况只能匹配周围一个时间步的的情况,也就是不可能跨过某个点去匹配,只能和自己相邻的点对齐;
3)单调性:路径一定是随时间单调递增的。
2.3.2、KMeans
在定义了时间序列数据的相似度之后,就可以采用KMeans算法对时序数据进行聚类操作。
它的基本思想是,通过迭代寻找K个簇(Cluster)的一种划分方案,使得聚类结果对应的损失函数最小。其中,损失函数可以定义为各个样本距离所属簇中心点的误差平方和:



2.4、降维
针对聚类完成后期货基本面数据,本报告对数据进行降维的操作。由于基本面数据彼此之间的相关性较高,且单条数据对期货价格的解释强度低于价量数据,基于以上原因,考虑首先对基本面数据进行降维操作,一方面可以提升单个因子的解释力度,另一方面可以降低模型的复杂程度,以加快模型运行效率。
本报告中涉及两种降维方式,以下对两种降维方式作简要介绍:
2.4.1、PCA
主成分分析算法(PCA)是最常用的线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的信息量最大(方差最大),以此使用较少的数据维度,同时保留住较多的原数据点的特性。
PCA降维的目的,就是为了在尽量保证“信息量不丢失”的情况下,对原始特征进行降维,也就是尽可能将原始特征往具有最大投影信息量的维度上进行投影。将原特征投影到这些维度上,使降维后信息量损失最小。其算法步骤如下:
设有m条n维数据:

在进行PCA降维之后,可以缓解维度灾难,并对数据进行降噪,同时将数据压缩到低维之后,使得降维之后的数据各特征相互独立。但是在另一方面,由于PCA保留了主要信息,舍弃了一些看似无用的信息,但这些“无用信息”只是在训练集上没有有效表现,因此产生了过拟合的可能性,这一问题在模型训练时需要注意。
2.4.2、KPCA
针对非线性的数据,KPCA(核函数主成分分析法)将非线性可分的数据转换到一个适合对其进行线性分类的新的低维子空间上。利用核PCA可以通过非线性映射将数据转换到一个高维空间中,在高维空间中使用PCA将其映射到另一个低维空间中,并通过线性分类器对样本对其划分。

2.5、回测框架
本报告依据OLS进行滚动回归预测。OLS(普通最小二乘法)多元回归的原理为,最优拟合曲线使得各点到直线的距离的平方和(残差平方和RSS)最小:
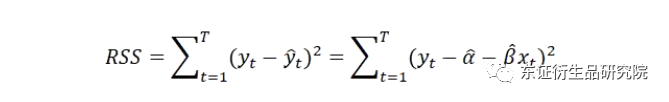
本报告采用滚动回归的方式进行回测,以避免使用未来数据。以周度预测为例,首先设置相应的滚动回归窗口长度N,对每一天T都截取T-N到T时间段的基本面数据,由于为周度预测,需要对基本面数据进行5天的移动处理,所以实际可用数据点为N-5天内的数据,随后根据训练模型得到一列预测值,再根据预测值与真实值的比较去构造回测模型。
回测过程基于历史窗口长度为240个交易日的基本面周度数据对未来一周的收益率进行滚动回测,回测为周频级别。

3
聚类降维实证
基于繁微数据平台,本报告共整理铜相关基本面因子共392个,这些因子涵盖了铜的上下游产业链相关数据,包括库存、原料端、进出口等相关数据,数据来源以Wind和上海钢联为主,经过初步筛选过后,剩余198个数据。
3.1、不聚类直接降维
首先不进行聚类,直接滚动降维,选取参数滚动窗口为240天,信息保留度为90%,经观察,滚动降维后的数据维度保持在11至14维。接下来根据拟合结果进行回测,模型会在每一次换仓日滚动建模,根据每一次更新后的模型对最新一期的数据进行收益率预测,根据预测收益率的正负进行相应多空操作。
回测结果显示,长期来看年化收益较为显著,达到19.79%,然而由于在2022年6-7月份铜期货价格发生暴跌,暴跌前期信号并未及时调整导致在这波行情中策略产生较大回撤。胜率略高于0.5,达到0.54,夏普值为0.43。此外预测值对于真实收益率的R-square达到23.59%。


考虑到预测收益率会给出一些很小的值,这些值的信号强度并不显著,不应直接生成多空信号,为了改进回测结果,设置多空阈值,只有当预测收益率的绝对值大于该阈值时才进行相应的多空操作。为了验证这样的猜想,统计模型的累积预测正确率随阈值逐渐下降的改变。通过下图可以观察到,除了前期由于预测点较少导致曲线波动外,随着阈值逐渐减少到0,模型预测的累积正确率向下收敛到55%左右,该数据验证了之前的猜想,即预测收益率绝对值越大,信号强度越明显,相应的预测正确率也越高。

尝试将阈值设置为1%,即只有预测收益率大于1%或小于-1%时才进行相应多空操作,结果如下。从回测指标来看,年化收益并无太大改变,而年化波动显著降低,夏普值也相应提升了,最大回撤控制在-10.39%,胜率达到了0.71。此外,收益曲线图像表明,策略整体收益更为稳健,整体开仓时间显著减少。

事实表明,设置合理的开仓阈值有助于策略整体表现的提升。然而,阈值是否“合理”取决于个人的投资偏好。数据表明,开仓阈值越高,策略整体胜率越高,但收益率会降低,另一方面,随着开仓阈值提升,策略开仓次数显著减少,意味着策略的容错率降低,故阈值的选择显得十分重要,下表展示了各个阈值下策略的各项回测指标,读者可以作为参考。

上图显示,当阈值小于1%时,年化收益并无明显区别,而当阈值大于1%时,随着阈值增大,年化收益逐渐降低;年化波动率和最大回撤均随着阈值增加逐渐降低;夏普值在阈值为0.8%时为最高值;胜率随着阈值增加而变高。
3.2、聚类降维
在本节,根据上文提到的DTW+KMeans算法对筛选过后的数据进行降维。设置聚类数量为5,由于数据集数量较少,且各大类数据存在明显差异,故KMeans算法收敛速度较快,大约5次之内就收敛,故将迭代次数设置为5次。下列表格为聚类结果,共五类,每类因子个数为11到23个不等,表格中标红数据为每类的“中心”。





通过聚类表可以发现,聚类得到的结果与我们的直觉存在一定出入,一些看似具有高相关性的数据被分到了不同的类别当中,比如Cluster1中的“进口数量:阳极铜:美国:当月值”与“LME铜:库存:韩国:釜山”距离较近,而同样是阳极铜进口数据的Cluster3中的“进口数量:阳极铜:智利:当月值”与“进口数量:精炼铜:印度:当月值”距离较近,由于此处的度量为DTW距离度量,能够有效提取时间序列数据的时序特征,故聚类结果与人工分类结果存在差异。
下列图表分别展示了阈值为0%和1%时,各类别的回测指标,同时也展示了在阈值为0%时,各类别的回测曲线。数据表明,除cluster0表现不尽如人意之外,其余类别的表现均展示了较好的预测能力。不同阈值的设置对回测结果的影响与上文的讨论一致,随着阈值的升高胜率提升,盈亏比下降。






同样尝试在不同阈值下,全部大类聚类降维后的回测结果。数据显示,聚类降维的方式相较于直接降维表现出明显的提升,在个别阈值下(0.04%),策略的年化收益达到了30%,相应地,夏普值也达到了0.75以上。


此外,尝试另外一种结合各大类信号的方式,即采用等权重的方式进行结合。将五大类信号单独导出,再根据等权重的方式合成综合信号,从结果来看,对于等权合成信号,阈值越小信号表现越好。整体来看,等权合成的方式相较于全量降维,各回测指标均有小幅提升。


4
多品种策略
在上文中,铜期货的回测结果表明聚类降维的方式相较于直接降维能够起到一定的提升,然而模型有效性的验证显然在一个品种上是远远不够的。在本章节,基于期货市场关注度较高的几大品种运用上述方式进行进一步验证。期货品种的选择不仅考虑到市场关注度,同时也覆盖了各大期货分类,具体为:有色金属(镍、锌);黑色系(螺纹钢、铁矿石、焦炭);能源化工(PTA、PP);农产品(豆粕)。
此外,在本章节最后,基于各个期货品种的预测数据,构建横截面上的多空策略,目的是提升策略整体的稳健性。
4.1、豆粕
在阈值为0时,豆粕的回测结果显示策略表现为:年化收益26.74%,年化波动59.9%,夏普值0.41,最大回撤-37.63%。整体来看,收益率较为可观,然而策略波动率较高,相应的最大回撤也较大。


4.2、PP
在阈值为0时,PP的回测结果显示策略表现为:年化收益24.19%,年化波动61.85%,夏普值0.35,最大回撤-51.36%。PP策略在2018年至2019年这两年时间里面出现了较长周期的回撤,且回撤幅度较大,达到了-51.36%。


4.3、PTA
在阈值为0时,PTA的回测结果显示策略表现为:年化收益18.04%,年化波动60.84%,夏普值0.26,最大回撤-38.59%。PTA策略整体收益情况不及PP,但在风险控制层面表现较好,最大回撤为-38.59%。


4.4、镍
在阈值为0时,镍的回测结果显示策略表现为:年化收益26.92%,年化波动81.54%,夏普值0.3,最大回撤-48.26%。在2020年之前镍的回测结果较为理想,然而在2020年之后策略净值出现较为明显下滑,策略整体的年化波动率达到了81.54%,表明该策略在镍上的风险较高。


4.5、锌
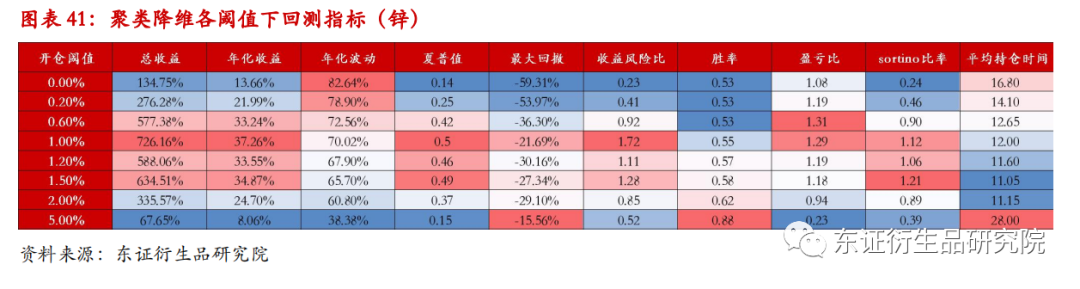
在阈值为0时,锌的回测结果显示策略表现为:年化收益13.66%,年化波动82.64%,夏普值0.14,最大回撤-59.31%。锌的策略虽然取得了13.66%的正收益,但是波动较为剧烈,最大回撤接近60%,导致策略的夏普值只有0.14.

4.6、螺纹钢
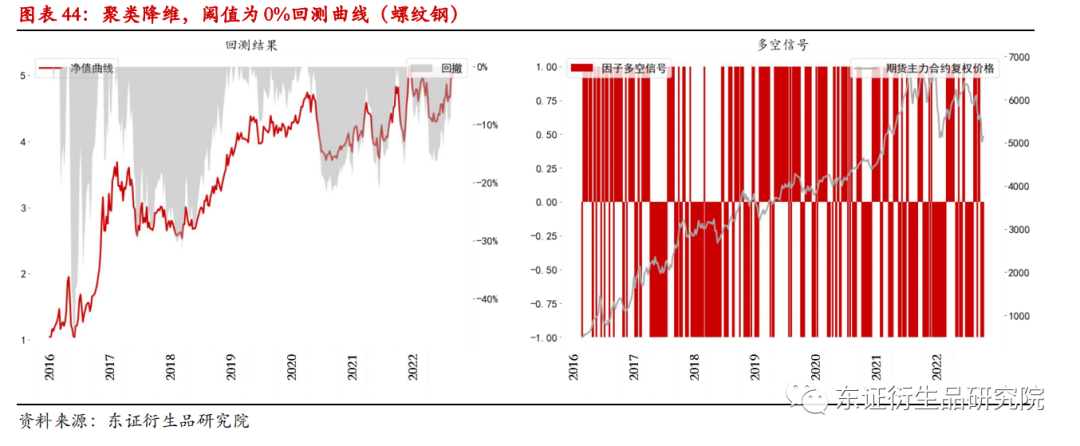
在阈值为0时,螺纹钢的回测结果显示策略表现为:年化收益27.24%,年化波动85.31%,夏普值0.29,最大回撤-46.62%。螺纹钢的大幅回撤主要发生在2016年初的价格剧烈波动,改策略在近些年表现较为稳定。

4.7、铁矿石
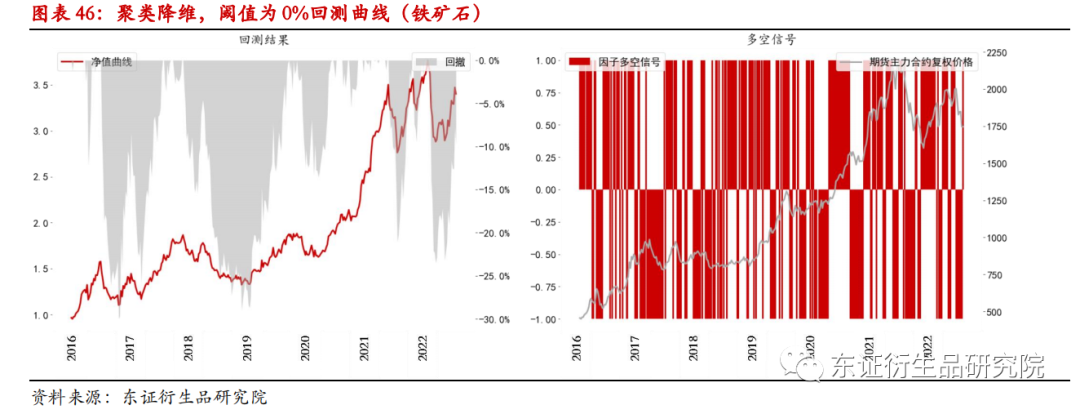
在阈值为0时,铁矿石的回测结果显示策略表现为:年化收益20.16%,年化波动50.00%,夏普值0.36,最大回撤-30.00%。同为黑色系的铁矿石相较于螺纹钢表现更好,在阈值为0的情况下,胜率达到了0.58。

4.8、焦炭
在阈值为0时,焦炭的回测结果显示策略表现为:年化收益27.40%,年化波动84.74%,夏普值0.330,最大回撤-66.40%。焦炭策略在2020年中出现幅度较大的回撤,最大回撤达到了-66.40,风险程度较高,子2021年开始逐渐修复该回撤。


在回测了几大主流品种之后,其回测结果显示出一定的共性:策略可以提供显著的正向收益,然而整体波动较大,最大回撤也较高;胜率均高于50%,范围在52%到56%不等,夏普值0.14到0.59不等。
数据结果表明,该策略对于单品种而言能够提供具有预测能力的信号,只需将策略的波动率进行控制即可,一个显而易见可以提高策略稳定性的方式就是纳入多个品种去构建横截面的多空策略。
5
多品种横截面多空模型
5.1、各品种等权构建
基于上述期货品种的回测结果,尝试构建横截面多空策略,策略共包括九大期货品种(铜、镍、锌、螺纹钢、铁矿石、焦炭、PTA、PP、豆粕),构建逻辑为在每个换仓周期,做多3个预测收益率最高的品种,做空3个预测收益率最低的品种,排名中间的3个进行空仓。本报告不重点研究仓位的权重分配策略,为简单起见,将做多与做空品种进行等权处理。此外,与前述对单品种的研究不同的是,由于多品种的多空机制的问题,不设置阈值参数。
下面展示了多品种策略的净值曲线以及回测指标。从净值曲线上来看,整体收益较为平滑,并未出现明显的回撤阶段;具体到回测指标,策略整体的年化收益达到26.85%,年化波动25.82%,夏普值0.95,最大回撤-13.62,胜率0.61,由于回测阶段未考虑到交易滑点,真实年化收益率应当略低于该值。

多品种策略的净值曲线显著好于单品种策略,由于该策略对于在品种做多上的仓位等于做空的仓位,故该策略为中性化策略,规避了期货市场的beta风险,这一点从收益曲线可以看出,该策略与整个商品市场的整体涨跌关系较低。由于策略考虑了九大品种的交易信号,故在单品种上出现的较大回撤某种程度上被策略平滑掉了。

5.2、基于波动率对信号强度调整
根据收益率排序进行品种多空选择可能存在一些问题:对于波动率比较高的品种,被选择的概率更高;而波动率较低的品种,被选择的概率更低,导致空仓概率过高。下图统计各品种的历史长期波动率和在策略组合中的空仓比例(空仓次数/总开仓次数)。结果表明,波动率较低的品种(如铜、铁矿石)空仓比例较高,以铜为例,其空仓比例达到了54.17%,而具有最高波动率的螺纹钢,其空仓比例只有27.38%。

为了尽可能均衡各品种的空仓比例,尝试基于各品种一段时间内的价格波动率对预测信号的强度进行调整,即将每一期的预测收益率除以当期之前一段时间内的价格波动率,再基于调整后的收益率进行回测。下图分别展示了基于10天、20天、30天、60天、90天内价格波动率调整后各品种的空仓比例(NA表示未调整),数据表明在调整后,各品种空仓比例仍然存在较大差异,原因在于该调整方式是利用实际历史波动率对预测收益率进行调整,而在该模型当中预测值的波动与真实值的波动窜较大差异,导致调整后仍然有较多品种空仓时期过多。因此,在最后一列加入了基于预测收益率序列的波动率进行调整,以此作为参照可以发现,该种调整方式可以有效均衡各品种的空仓时间。

调整后,策略的表现如下图:基于预测收益率序列的波动率进行调整后策略整体表现反而更差,然而年化波动率是所有策略中最低的。分析原因,在于模型对于波动率较高的品种预测能力偏强,波动率较高的品种其预测信号的强度往往更加显著,模型在这些品种上的表现也更高。故均衡空仓时间之后,策略整体收益降低,但整体波动率也进一步降低。

5.3、基于波动率对权重进行调整
另外一种基于波动率调整的方式是摒弃横截面等权的思路,直接基于波动率构建各品种的权重矩阵,根据该矩阵进行回测,这样一来也就不存在某些空仓时间过多的问题,任何时刻每个品种都有一定的仓位。回测结果如下图,同样展示了基于10天、20天、30天、60天、90天内价格波动率调整后的策略表现。该调整对参数敏感性较强,且波动率计算周期越短,策略整体表现较好,但相应的年化波动率也越高。

6
结论
本文提出了一种新的期货收益率预测模型中基本面数据处理的方法:通过DTW+KMeans的方式对数据进行分类,再基于分类数据对期货收益率进行预测。相较于全量降维的方式,回测结果显示该模型对于策略整体的预测能力有一定提升。
此外,为提升策略的稳健性,可以通过设置相应的开仓阈值,阈值的提高能够提升策略的胜率,然而同时也会降低其收益率和盈亏比,实证表明,阈值设定为1%是一个较为有效的参数。
在选择基本面数据的过程中,我们建议对数据进行一定的筛选。有效的筛选不仅可以降低模型的复杂性,还可以避免过多的无效、冗余数据,为后续的建模提供坚实的基础。
模型的有效性在多个品种的回测上均得到验证,结果表明,对于多数品种,该策略均能带来显著正收益,唯一需要担忧的是在一些市场波动剧烈时段,单品种的回撤风险较大。故可以构建多品种横截面策略以降低策略回撤,与预期的一样,多策略模型相较于单品种模型具有更高的稳健性。在策略中,尽可能地纳入更多的期货品种可以带来更为平滑的收益曲线。
在报告最后考虑了基于波动率对仓位进行调整:若对信号强度进行调整,策略整体并无太大提升,原因在于策略对波动率较高品种的预测能力更强,而调整之后波动率较高的品种持仓次数降低;若对权重进行调整,策略表现对参数敏感性较大,波动率计算周期越短,策略收益越高,年化波动也相应增高。
本文来源于网友自行发布,不代表本站立场,转载联系作者并注明出处